🔄 Pipeline ETL con SSIS - Segmentación de Datos
Flujo de extracción, transformación y carga con división condicional
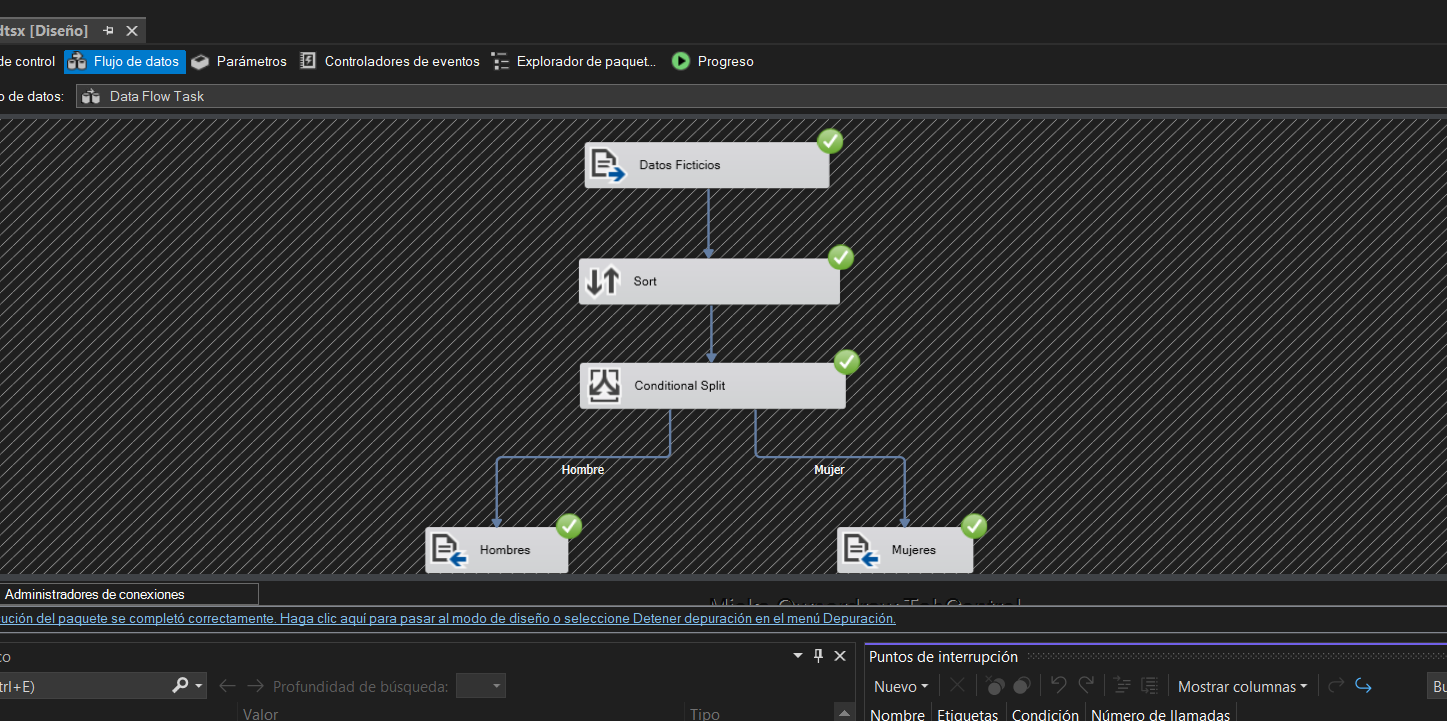
🔀 Patrón ETL: Segmentación por Género con Conditional Split
Pipeline ETL básico que demuestra la extracción de datos ficticios, ordenamiento mediante Sort, y división condicional (Conditional Split) para segmentar registros por género. Los datos se dirigen automáticamente a dos destinos separados: tabla de Hombres y tabla de Mujeres, permitiendo análisis diferenciado por segmento demográfico.
📚 Ejemplos Adicionales de Patrones ETL

🔀 Patrón ETL: Combinación de Mezcla (Merge Join)
Este flujo avanzado demuestra la integración de datos desde dos fuentes diferentes (Data Steep y Data Mart). Los datos se ordenan mediante componentes Sort, luego se combinan con Merge Join para identificar diferencias entre ambas fuentes, y finalmente se utiliza Conditional Split para filtrar y cargar solo los productos nuevos en el destino. Este patrón es ideal para sincronización de datos y carga incremental.

🔄 Patrón ETL: Integración Multi-Fuente con Lookup
Flujo avanzado que integra datos de tres fuentes de clientes diferentes. Utiliza componentes de Data Conversion para estandarizar formatos de datos, Sort para ordenar registros, y Merge para consolidar información de múltiples fuentes. Los componentes Lookup enriquecen los datos con información adicional de tablas de referencia. Finalmente, el Conditional Split dirige los registros a tablas intermedias según reglas de negocio específicas, permitiendo procesamiento diferenciado.
📋 Descripción del Proyecto
Este proyecto demuestra la implementación de un pipeline ETL completo utilizando SQL Server Integration Services (SSIS). El flujo de datos está diseñado para procesar información de manera eficiente, aplicando transformaciones y dirigiendo los datos a diferentes destinos según criterios de negocio específicos.
Objetivo Principal
Diseñar un flujo de datos escalable que permita la segmentación automática de información basada en atributos específicos, facilitando el análisis diferenciado y la generación de reportes personalizados por segmento.
🔧 Componentes del Flujo de Datos
1. Datos Ficticios (Fuente de Datos)
Componente de origen que simula la extracción de datos desde una fuente externa. En un escenario real, esta fuente podría ser:
- Base de datos SQL Server
- Archivo CSV o Excel
- API REST externa
- Servicio cloud (Azure, AWS)
2. Sort (Ordenamiento)
Transforma los datos ordenándolos según uno o más criterios. Esto es esencial para:
- Optimizar el rendimiento de operaciones posteriores
- Preparar datos para operaciones de merge o join
- Facilitar la detección de duplicados
- Mejorar la legibilidad de datos de salida
3. Conditional Split (División Condicional)
Componente clave que evalúa condiciones lógicas y dirige los datos a diferentes rutas según el resultado. En este caso, segmenta por género:
📍 Ruta: Hombre
IF (Genero == 'Hombre' OR Genero == 'M')
📍 Ruta: Mujer
IF (Genero == 'Mujer' OR Genero == 'F')
4. Destinos (Hombres y Mujeres)
Los datos segmentados se cargan en destinos separados para análisis diferenciado:
🗃️ Tabla: Hombres
Registros masculinos
🗃️ Tabla: Mujeres
Registros femeninos
💼 Casos de Uso Prácticos
📊 Marketing Segmentado
Separar datos de clientes por género para crear campañas de marketing personalizadas y medir su efectividad de manera independiente.
📈 Análisis Demográfico
Generar reportes específicos por segmento demográfico para identificar patrones de comportamiento y preferencias diferenciadas.
🏥 Salud y Bienestar
Segmentar datos médicos para análisis estadísticos específicos por género, considerando diferencias en condiciones de salud y tratamientos.
🛍️ E-commerce
Personalizar recomendaciones de productos y analizar patrones de compra según el género del cliente para optimizar el inventario.
⭐ Ventajas de usar SSIS
🎨 Interfaz Visual Intuitiva
Diseño drag-and-drop que facilita la creación y mantenimiento de flujos ETL complejos sin necesidad de escribir código extenso.
🚀 Alto Rendimiento
Procesamiento paralelo y optimizado que permite manejar grandes volúmenes de datos de manera eficiente.
🔌 Múltiples Conectores
Conectividad nativa con diversas fuentes de datos: SQL Server, Oracle, MySQL, Excel, CSV, APIs, servicios cloud, y más.
🔄 Reutilización de Componentes
Creación de paquetes reutilizables y plantillas que aceleran el desarrollo de nuevos flujos ETL.
📊 Monitoreo y Logging
Capacidades integradas de registro, auditoría y monitoreo que facilitan el troubleshooting y la optimización.
🔐 Seguridad Empresarial
Integración con Active Directory, encriptación de datos sensibles y control granular de permisos.
🛠️ Tecnologías y Herramientas
SQL Server Integration Services (SSIS)
Plataforma principal para desarrollo de flujos ETL
SQL Server
Base de datos relacional para almacenamiento
Visual Studio / SSDT
Entorno de desarrollo integrado
T-SQL
Para consultas y transformaciones complejas
SQL Server Agent
Para programación y automatización
SSMS
SQL Server Management Studio para administración
💡 Conclusiones
Este pipeline ETL demuestra cómo SSIS facilita la implementación de procesos de integración de datos complejos de manera visual e intuitiva. La capacidad de segmentar datos dinámicamente permite crear arquitecturas de datos más flexibles y orientadas al análisis específico de cada segmento de negocio.
3
Etapas principales
(Extract, Transform, Load)
2
Destinos segmentados
(Análisis diferenciado)
100%
Automatización
(Cero intervención manual)